React组件的性能优化
单个React组件的性能优化
React通过Virtual DOM来提高组件渲染的性能, 通过最小修改的方式刷新真实DOM
但是, 对比Virtual DOM依然是不小的性能开销, 尽量在计算和对比之前判断渲染结果是否有变化
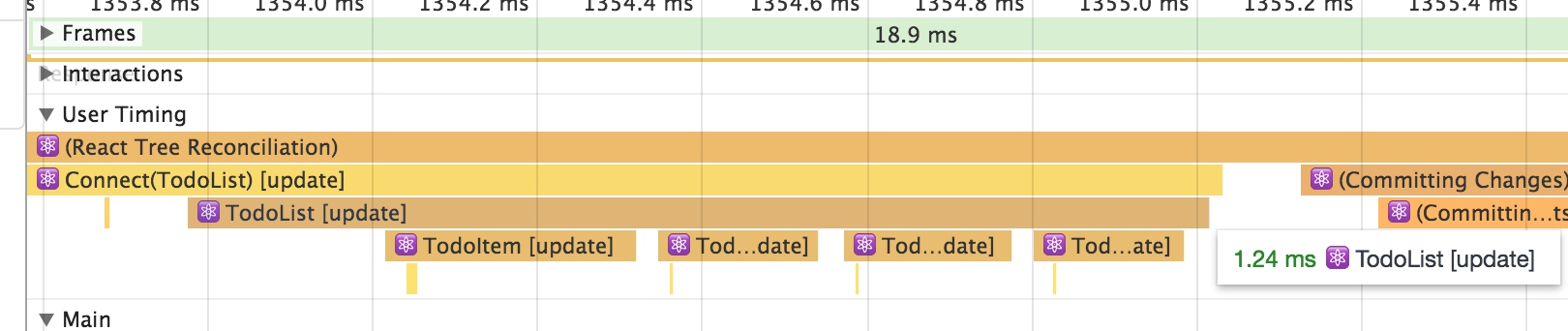
在界面上切换一个任务的完成状态, 可以看到, 页面上所有的TodoItem都被刷新, 而实际上需要刷新的只有一个TodoItem:
“过早优化是万恶之源”
所谓的”过早优化”指的是没有量化证据的情况下, 开发者对性能优化的猜测, 对于性能有关键影响的部分, 优化并不嫌早.
如果能够优化性能的同时, 又能避免代码变得复杂, 何乐而不为
在我们的例子中, 对于实例数量是动态的组件, 一点点时间的浪费会随着数量增多而累积成为很长的时间
利用组件声明周期中的shouldComponentUpdate函数来避免多余的刷新:
// TodoItem.js
shouldComponentUpdate(nextProps, nextState) {
return (nextProps.text !== this.props.text) || (nextProps.completed !== this.props.completed)
}

可以看到, 优化之后TodoItem的刷新只进行了一次, 整个列表的刷新时间从1.24ms降低到1.06ms
如果在每个组件中都编写shouldComponentUpdate会是一件非常繁琐的工作, 好在react-redux的connect方法内置了该方法的实现, 但是需要注意, 内置的方法是进行浅层对比, 在我们的例子中, 即使将TodoItem改造为connect模式, 也无法避免渲染:
export default connect()(TodoItem)

原因在于TodoList组件中的使用方式, onToggle和onRemove每次都会创建一个新的匿名函数, 这对于浅层比较来说, 每次的props都是不同的:
<TodoItem
key={todo.id}
text={todo.text}
completed={todo.completed}
onToggle={() => onToggle(todo.id)}
onRemove={() => onRemove(todo.id)}
/>
解决方法有两个:
- onToggle和onRemove指向唯一确定的函数
- 将onToggle和onRemove封装在TodoItem内部
第二种方案使得组件的内聚性更好, 这里只实现第二种方案:
// todoList.js 增加一个id字段
<TodoItem
id={todo.id}
key={todo.id}
text={todo.text}
completed={todo.completed}
/>
function mapStateToProps(state = [], ownProps) {
return {
todos: filterByCompleteState(state.todos, state.filter)
}
}
// 移除动作分发
export default connect(mapStateToProps)(TodoList);
// TodoItem.js
import React from 'react';
import { connect } from 'react-redux';
import { toggleTodo, removeTodo } from '../actions'
const TodoItem = ({ text, completed, onToggle, onRemove }) => (
<li className="list-group-item">
<input type="checkbox" checked={completed ? 'checked' : ''} onClick={onToggle} />
<span>{text}</span>
<button className="btn btn-sm btn-light" onClick={onRemove}>x</button>
</li>
);
// 在内部处理动作分发
const mapDispatchToProps = (dispatch, ownProps) => {
const { id } = ownProps
return {
onToggle: () => dispatch(toggleTodo(id)),
onRemove: () => dispatch(removeTodo(id))
}
}
export default connect(null, mapDispatchToProps)(TodoItem)
可以看到, 只执行了一个TodoItem的刷新

多个React组件的性能优化
在上面, 我们根据单个组件的声明周期进行了优化
但是在应用中往往是多个组件呈树形组合而成的
在多个组件组合时, 依然考虑三个声明周期: 装载, 更新, 卸载
其中装载和卸载没有什么优化空间, 重点是更新阶段
调和(Reconfiliation): React对比原有Virtual DOM和新的Virtual DOM, 寻找差异的过程
在理论上, 对比两个N个节点的属性结构的算法, 事件复杂度是O(N^3), 但是实际上React采用的算法是O(N)
这种算法不是最精准的, 但是是性能和复杂度的最好折中
- 从根节点开始递归
- 节点类型不同时, 直接认为子树已经无用, 整体进行卸载和重新装载
- 如果节点类型相同, 而且节点是DOM节点, 则只刷新属性和内容
- 如果节点类型相同, 而且节点是React组件, 则经历组件的更新声明周期
- 处理完节点的更新后, 继续递归处理他的子节点
对于多个子组件构成的序列
<ul>
<TodoItem text="first" />
<TodoItem text="second" />
</ul>
如果在最后新增了一个子组件:
<ul>
<TodoItem text="first" />
<TodoItem text="second" />
<TodoItem text="third" /> // new
</ul>
配合上文中shouldComponentUpdate的判断, 会只更新第三个新增组件
但是如果将组件在前面添加:
<ul>
<TodoItem text="zero" /> // new
<TodoItem text="first" />
<TodoItem text="second" />
</ul>
React不会精确的对比差别, 而是认为三个组件都更新了
克服这种问题的方式就是给序列的每个元素加上一个key, 辅助React进行更智能的判断
<ul>
<TodoItem key={0} text="zero" /> // new
<TodoItem key={1} text="first" />
<TodoItem key={2} text="second" />
</ul>
如果开发者忘记使用key, React会通过警告的方式进行提醒
- key要唯一
- key要稳定, 不要用数组下标作为key
用reselect提高数据获取性能
前面的例子都是通过优化渲染过程来提高性能, 既然React和Redux都是通过数据驱动的, 那么也可以通过优化数据获取过程来优化
function filterByCompleteState(todos, filter) {
switch (filter) {
case FilterTypes.ALL:
return todos;
case FilterTypes.COMPLETED:
return todos.filter(todo => todo.completed)
case FilterTypes.UNCOMPLETED:
return todos.filter(todo => !todo.completed)
default:
return todos;
}
}
function mapStateToProps(state = [], ownProps) {
return {
todos: filterByCompleteState(state.todos, state.filter)
}
}
通过mapStateToProps从store中获取数据, 这里的mapStateToProps函数一定要快
在这个例子中, 如果数组较大, 每次遍历数组都是不小的性能开销
两阶段选择过程
实际上, 如果所有的待办事项没有发生变化, 就没有必要重新执行, 可以将结果缓存并直接使用缓存结果
这就是reselect的工作原理: 如果相关状态没有改变, 就使用缓存的结果
reselect库用来创造选择器, 所谓选择器就是一个接受state作为参数的函数, 结果就是mapStateToProps的计算结果.
选择器不是纯函数, 因为他会产生副作用: 记忆结果并返回记忆结果
reselect将选择器的工作分为两个步骤:
- 步骤1 从state中获取第一层结果, 并与上一次的结果比较, 如果没有发生变化就跳过第二步, 比较是通过===进行的
- 步骤2 根据第一层结果, 计算chunk选择器需要返回的最终结果
第一层计算每次都要进行, 所以一定要快, 最好就是一次映射, 将字段的引用从state中取出来, 复杂的计算交给第二步来进行
$ yarn add reselect
// todos/reselector.js
import { filterTypes as FilterTypes } from '../filter'
import { createSelector } from 'reselect'
const getFilter = (state) => state.filter
const getTodos = (state) => state.todos
export const filterByCompleteState = createSelector(
[getFilter, getTodos], // 使用lambda表达式进行映射
(filter, todos) => {
switch (filter) {
case FilterTypes.ALL:
return todos;
case FilterTypes.COMPLETED:
return todos.filter(todo => todo.completed)
case FilterTypes.UNCOMPLETED:
return todos.filter(todo => !todo.completed)
default:
return todos;
}
}
)
// todoList.js
import {filterByCompleteState} from '../selector'
function mapStateToProps(state = [], ownProps) {
return {
todos: filterByCompleteState(state) // 使用选择器的计算结果
}
}
Redux要求每个reducer不能修改state状态, 如果发生变化, 一定是一个新对象, 所以如果对象引用没有改变, 我们就可以确定内容没有改变, 在reselect中就可以直接使用缓存结果
reselect并不是绑定在React或Redux体系中, 可以在任何需要记忆的场景下都可以使用
范式化状态树
状态树的设计应该扁平化和范式化, 避免出现冗余数据
例如要给todo添加一个分类信息, 如果采用反范式化设计:
{
id: 1,
text: "todo 1",
completed: false,
type: {
name: "type1",
}
},
{
id: 2,
text: "todo 2",
completed: false,
type: {
name: "type1",
}
}
而采用范式化设计, 每个todo中只记录type的id, 分类信息被记录在types节点下:
{
id: 1,
text: "todo 1",
completed: false,
typeId: 1
},
{
id: 2,
text: "todo 2",
completed: false,
typeId: 1
}
范式化的好处是, 如果需要修改type信息时, 会非常容易处理. 只需要修改types下的信息.
缺点是每次获取todo都需要关联types进行查找, 实际上如果使用reselect, 大部分情况下都会命中缓存, 也就没有花费多少join的时间
总结
- 性能优化的要点: 避免传递给props的是一个不同的对象
- React通过一个折中的算法, 实现O(N)复杂度的对比过程
- 不能随意修改跟节点的类型, 否则会导致整个子树的重新装载
- 列表形式的子节点, 使用key来帮助react进行判断
- reselect库通过两阶段计算和缓存来提高性能
- 状态树应该扁平, 范式化, 这样有利于保持数据一致性
React高阶组件
“重复是优秀系统设计的大敌”
在开发过程中, 经常会发现某些功能被多个组件使用, 但是这些功能与界面无关, 不能简单的抽取为新的组件, 这时就需要构造更灵活, 更易于复用的高阶组件
概念
高阶组件(HOC)并不是React提供的某种API, 而是使用React的一种模式, 用于增强现有组件的功能
高阶组件就是一个函数, 接受一个组件作为参数, 返回一个新的组件作为结果, 新的组件拥有了输入组件不具有的功能
import React from 'react'
function removeUserProp(WrappedComponent) {
return class WrappingComponent extends React.Component {
render() {
const {user, ...otherProps} = this.props // 过滤掉user属性
return <WrappedComponent {...otherProps} />
}
}
}
- removeUserProp是一个高阶组件, 严格来说是一个高阶组件工厂函数
- WrappedComponent是被增强的组件类
- WrappingComponent是增强后的组件类
- 这两个组件的名称并不重要, 因为都只是局部变量
使用的时候:
const NewComponent = removeUserProp(SampleComponent)
NewComponent可以作为一个组件来使用, 区别是SampleComponent关心user属性, 而NewComponent直接无视user属性
高阶组件的意义
- 重用代码, 封装相同的逻辑
- 修改现有的React组件, 针对已有的或者第三方组件进行扩展
高阶组件的分类
- 代理方式的高阶组件
- 继承方式的高阶组件
代理方式的高阶组件
上面的removeUserProp就是一个高阶组件, 特点是返回的组件继承自React.Component
在新建组件的render中把包裹的组件渲染出来, 除了自身的一些工作, 其余都转手给被包裹组件
如果增强行为不涉及生命周期, 也可以不维护自己的状态, 直接返回纯函数
function removeUserProp(WrappedComponent) {
return function newRender(props) {
const {user, ...otherProps} = props // 过滤掉user属性
return <WrappedComponent {...otherProps} />
}
}
操纵props
高阶组件负责新增, 删除, 修改props
function addNewProps(WrappedComponent, newProps) {
return function newRender(props) {
return <WrappedComponent {...otherProps} {...newProps} />
}
}
这种方式可以给不同的组件扩充不同的新属性
const FooComponent = addNewProps(DemoComponent, {foo: 'foo'})
const BarComponent = addNewProps(OtherComponent, {bar: 'bar'})
访问ref
ref引用并不是推荐的做法, 只是一种备选
const refsHOC = (WrappedComponent) => {
return class HOCComponent extends React.Component {
constructor(props) {
super(props)
this.linkRef = this.linkRef.bind(this)
}
linkRef(instance) {
this._root = instance // instance就是WrappedComponent组件实例的DOM节点
}
render() {
const props = {...this.props, ref: this.linkRef}
return <WrappedComponent {...props} />
}
}
}
ref的获取是在WrappedComponent组件装载的时候获取的
抽取状态
react-redux的connect函数就是抽取状态的使用, 注意, connect本身不是高阶组件, 他调用的结果产生另外一个函数, 这个函数才是高阶组件
其作用是将store与state的同步功能从无状态组件中提取出来, 代为管理
包装组件
在JSX中引入多个组件, 组合成为一个新的组件, 或者引入新的样式
const styleHOC = (WrappedComponent) => {
return class HOCComponent extends React.Component {
render() {
return (
<div style={style}>
<WrappedComponent {...props} />
</div>
)
}
}
}
const style = {color: 'red'}
const NewComponent = styleHOC(DemoComponent, style)
继承方式的高阶组件
采用继承关系关联新组件和参数组件
function removeUserProp(WrappedComponent) {
return class WrappingComponent extends WrappedComponent {
render() {
const {user, ...otherProps} = this.props // 过滤掉user属性
this.props = otherProps
return super.render()
}
}
}
与代理组件的最大区别是使用参数组件的方式, 继承方式的高阶组件中, 是通过super.render()调用来渲染
在渲染过程中, 代理方式经历两个生命周期, 而继承模式下只有一次
操纵props
唯一的场景就是高阶组件需要根据参数组件的渲染结果来决定如何修改props, 利用React.cloneElement来重新渲染
const modifyPropsHOC = (WrappedComponent) => {
return class NewComponent extends WrappedComponent {
render() {
const elements = super.render()
const newStyle = {
color: (elements && elements.type === 'div') ? 'red' : 'green'
}
const newProps = {...this.props, style: newStyle}
return React.cloneElement(elements, newProps, elements.props.children)
}
}
}
操纵生命周期函数
通过继承的方式, 重新定义生命周期函数, 这是继承组件的专用场景, 代理方式无法实现
const onlyForLoginHOC = (WrappedComponent) => {
return class NewComponent extends WrappedComponent {
render() {
if (this.props.loggedIn) {
return super.render()
} else {
return false
}
}
}
}
const cacheHOC = (WrappedComponent) => {
return class NewComponent extends WrappedComponent {
shouldComponentUpdate(nextProps, nextState) {
return !nextProps.useCache
}
}
}
优先使用组合, 然后才考虑继承
高阶组件的显示名
高阶组件会返回一个新的组件, 会丢弃参数组件的名称, 这在调试阶段是不方便的, 往往需要给高阶组件重新定义一个现实名
function getDisplayName(WrappedComponent) {
return WrappedComponent.displayName || WrappedComponent.name || 'Component'
}
HOCComponent.displayName = `Connect(${getDisplayName(WrappedComponent)})`
以函数作为子组件
高阶组件不是唯一复用的方式, 高阶组件主要是通过props来进行扩展
使用高阶组件有一个限制: 对参数组件的props有了固化的要求, 组件X必须能够接受高阶组件传递进来的props
这种限制给高阶组件的使用范围造成了局限, 而使用函数作为子组件的方式, 可以大大提高灵活性
class AddUserProps extends React.Component {
render() {
const user = loggedinUser
return this.props.children(user)
}
}
- AddUserProps - 首字母大写, 因为它是一个真的组件而不是函数
- children - 是子组件, 直接通过调用的方式传递参数
在使用的时候:
<AddUserProps>
{ (user) => <div>{user}</div> }
</AddUserProps>
通过中间函数的连接, 可以在其中包含各种逻辑, 给高阶组件的使用提供了最大的灵活性
性能优化问题
虽然以函数作为子组件十分灵活, 但缺点是难以进行性能优化
每次渲染都要调用函数, 而且无法通过生命周期函数进行处理