模块化
在本章中,我会解释这些模块是如 何工作的,并告诉你如何自己开发模块 Node的一个重要特性就是我们无需真正地辨别模块到底是我们自己编写的还是从外部仓库中获取的
编写简单模块
模块是Node.js对常用功能进行分组的方式 实际上Node.js中的每个文件都是一个模块 将多个文件、单元测试、文档和其他支持文件放在文件夹中,并打包成复杂的模块
exports.hello_world = () => {
console.log('hello world')
}
exports对象是一个特殊的对象,在每个我们创建的文件中由Node模块系统创建,当引入这个模块时,会作为require函数的值返回。被封装在每个模块的module对象中,用来暴露函数、变量或者类
测试文件如下:
const myModule = require('./hello-module')
myModule.hello_world()

一个模块中可以包含多个导出:
exports.hello_world = () => {
console.log('hello world')
}
exports.goodbye = () => {
console.log('goodbye')
}
模块经常被用来实现工厂模式:
class Greeting {
greeting() {
console.log('hello')
}
}
exports.createGreating = () => {
return new Greeting()
}
npm包管理器
除了编写自己的模块和使用Node.js提供的模块,我们还会频繁 地使用Node社区其他人编写并发布到互联网上的代码。现今最常用 的做法是使用npm(Node包管理器) npm将模块包安装到项目的node_modules/子目录下
常用命令:
npm install 安装模块
npm search 搜索模块
npm ls 查看模块
npm update 更新模块
使用模块
要在编写的Node文件中引入模块,需要使用require函数
var http = require('http')
使用时的查找规则:
- 如果请求的是内置模块——例如http或者fs——Node会直 接使用这些模块。
- 如果require函数的模块名以路径符开始(如./、../或者/), 那么Node会在指定的目录中查找模块并尝试去加载它。如果没有在模块名中指定.js扩展名,Node会首先查找基于同名文件夹的模块。 如果没有找到,它会添加扩展名.js、.json和.node,并依次尝试加载这些类型的模块(带有.node扩展名的模块会被编译成附加模块)。
- 如果模块名开始时没有路径符,Node会在当前文件夹的 node_modules/子文件夹下查找模块。如果找到,则加载该模块; 否则,Node会以自己的方式在当前位置的路径树下搜寻 node_modules/文件夹。如果依然失败,它会在一些默认地址下进行搜寻,例如/usr/lib和/usr/local/lib文件夹。
- 如果在以上任何一个位置都没有找到模块,则抛出错误
模块缓存
当模块从指定的文件或者目录上加载之后,Node.js会将它缓 存。之后所有的require调用将会从相同的地址加载相同的模块—— 而这些模块已经初始化或者做过其他工作
有时候两个文件中都尝试加载一个指定的模块,但得到的可能并不是同一个

如果main.js或者utils.js都引入mail_widget,由于Node的搜索规则,它会在项目的node_modules/子目录下发现该模块,最终获取mail_widget的1.0.0版本。但是,如果引入 special_widget,而这个模块也希望使用 mail_widget,special_widget会获取它自己私有的mail_widget版本,2.0.1版本在它自己的node_modules/文件夹下。
这是Node.js模块系统最强大和神奇的特性之一。许多其他的系统、模块、widget或动态库都集中存储在一个位置,当请求的包本身也需要请求其他不同版本的模块时,版本控制就成了梦魇。而在 Node中,可以自由地引入其他不同版本的模块,Node的命名空间和模块规则意味着它们之间不会互相干扰
循环引用
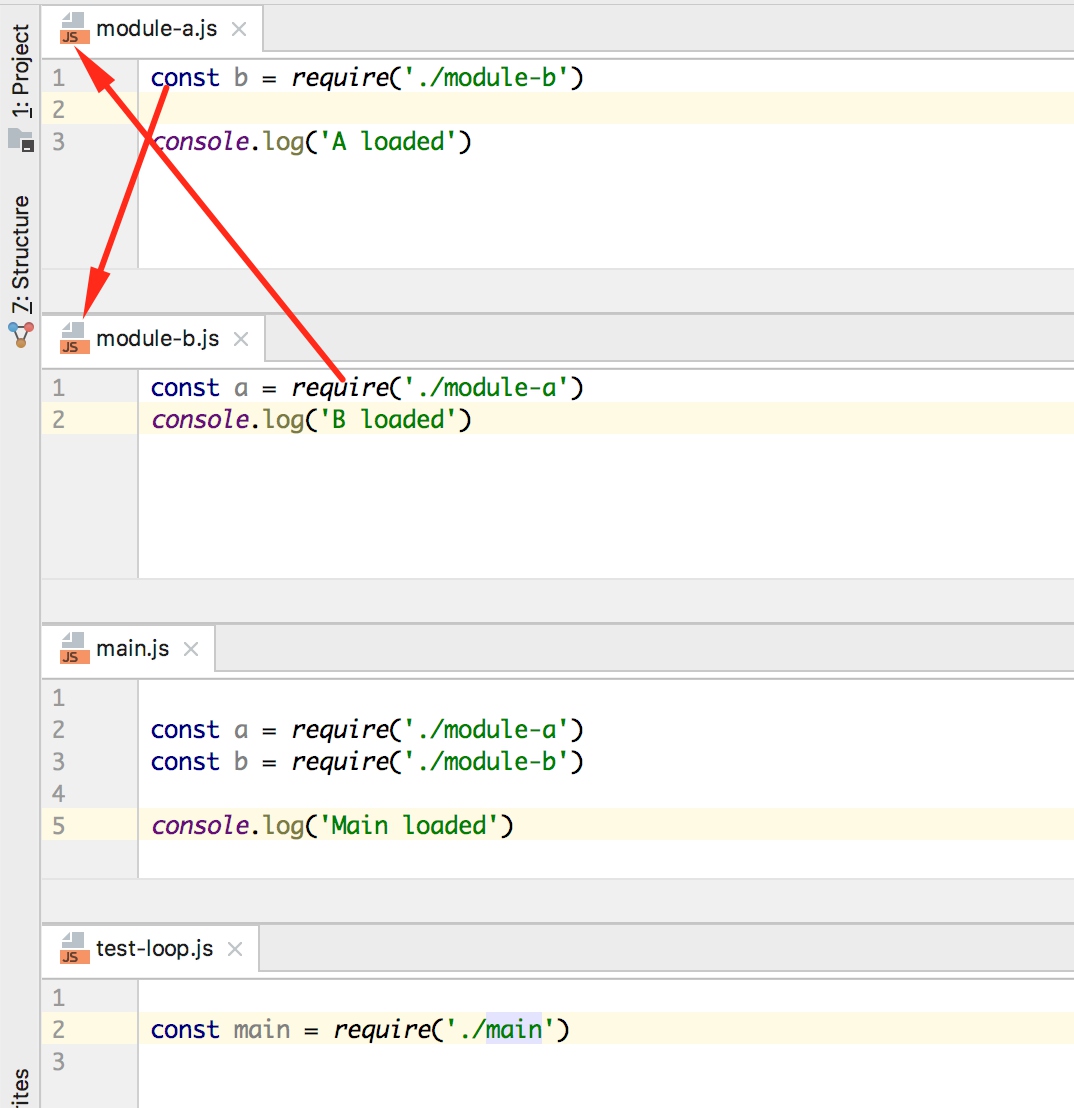
如上图所示,a和b之间存在循环依赖
执行test-loop时,nodejs能够检查到模块到初始化状态,避免循环到发生。
- main.js被加载,运行引入module-a.js的代码。
- module-a.js被加载,运行引入module-b.js的代码。
- module-b.js被加载,运行引入module-a.js的代码。
- Node探测到循环并返回一个指向module-a.js的对象,但不会再执行其他代码——在这一刻,module-a.js的加载和初始化并没有完成。
- module-b.js、module-a.js和main.js都完成初始化(按顺序),然后module-b.js和 module-a.js的引用都有效和可用。

编写模块
Node.js中每个文件都是一个含有module和exports对象的模块。但是我们也要清楚,模块也可以很复杂:包含一个目录用来保存 模块的内容和一个含有包信息的文件。
基本格式如下:
- 创建一个文件夹来存放模块内容
- 添加名为package.json的文件到文件夹中。文件至少包含当前模块的名字和一个主要的JavaScript文件——用来一开始加载该模块。
- 如果Node没有找到package.json文件或者没有指定主JavaScript文件,那它就会查找index.js(或者是编译后的附加模块 index.node)
创建模块
将我们之前创建的相簿管理作为模块,创建如下目录结构:
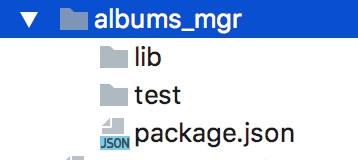
package.json中定义模块名称和入口文件:
{
"name": "albums_manager",
"version": "1.0.0",
"description": "",
"main": "./lib/album.js",
}
用来托管Node模块源代码的诸如github.com的网站如果发现有Readme.md文档,会自动地渲染并展示Readme文档
albums.js定义模块内容:
exports.getAlbumsList = () => {
// ...
}
使用现有模块
已定义如下模块:

想要在其他项目中使用该模块:
- 可以在package.json中添加
"private": true,告诉npm不能将现在还不想发布的模块发布到外部的npm源中。
- 接下来使用npm link命令,这个命令会告诉npm创建一个链接,指向当前机器默认公开包库的albums_manager包

- 其他想使用该模块的代码中,加入引用
const albums = require('albums_manager')
console.log(albums)
- 在终端连接到私有库

发布模块
- 将package.json中到private修改为false
- 执行npm adduser添加用户
- 补充package.json中的信息
- 执行npm publish发布模块
- 执行npm unpublish撤回发布
应当内置的通用模块 - async
考虑这种情况,我们想要编写一些异步的代码:
- 打开路径的句柄
- 判断路径是否指向一个文件
- 如果文件指向一个文件,加载这个文件的内容
- 关闭文件句柄并将内容返回给调用者
如果使用内置fs模块进行编写,依次调用open、stat、read、close等函数,方法很快就陷入深层的嵌套结构。
要解决这个问题,可以使用一个叫做async的npm模块 async 提供一个直观的方式来构造和组织异步调用
串行执行代码
分别通过waterfall和series
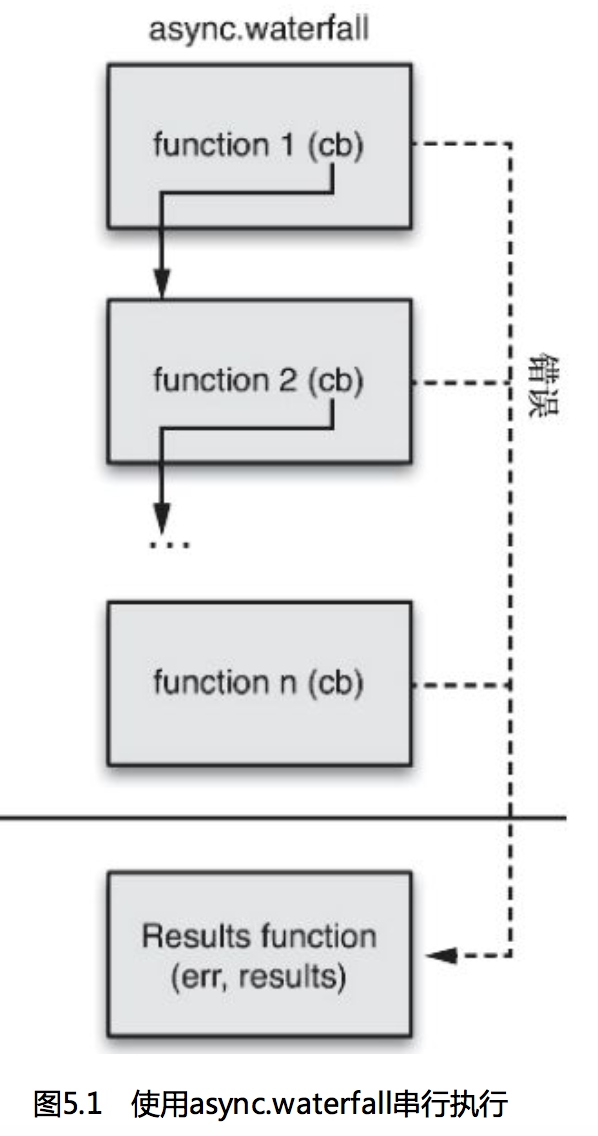
waterfall函数接收一个函数数组作为参数并一次一个地执行它们,然后把每个函数的结果传给下一个函数。结束时,结果函数会接收函数数组中最后一个函数的返回结果作为参数并执行。这种方式下,如果在任何一步出现错误,执行都会停止,结果函数会接收错误 信息。
function load_file_contents2(path, callback) {
var f;
async.waterfall([
function (cb) { // cb stands for "callback"
fs.open(path, 'r', cb);
},
// the handle was passed to the callback at the end of
// the fs.open function call. async passes ALL params to us.
function (handle, cb) {
f = handle
fs.fstat(f, cb);
},
function (stats, cb) {
var b = new Buffer(stats.size);
if (stats.isFile()) {
fs.read(f, b, 0, stats.size, null, cb);
} else {
calback(make_error("not_file", "Can't load directory"));
}
},
function (bytes_read, buffer, cb) {
fs.close(f, function (err) {
if (err)
cb(err);
else
cb(null, buffer.toString('utf8', 0, bytes_read));
})
}
],
// called after all fns have finished, or then there is an error.
function (err, file_contents) {
callback(err, file_contents);
});
}
async.series函数和async.waterfall有两个关键的不同点:
- 来自一个函数的结果不是传到下一个函数,而是收集到一个数组中,这个数组作为“结果”(第二个)参数传给最后的结果函数。依次调用的每一步都会变成结果数组中的一个元素
- 我们可以传给async.series一个对象,它会枚举每个key并执行每个key对应的函数。在这种方式下,结果不是作为一个数组传入,而是作为拥有相同key的对象被函数调用。

并行执行

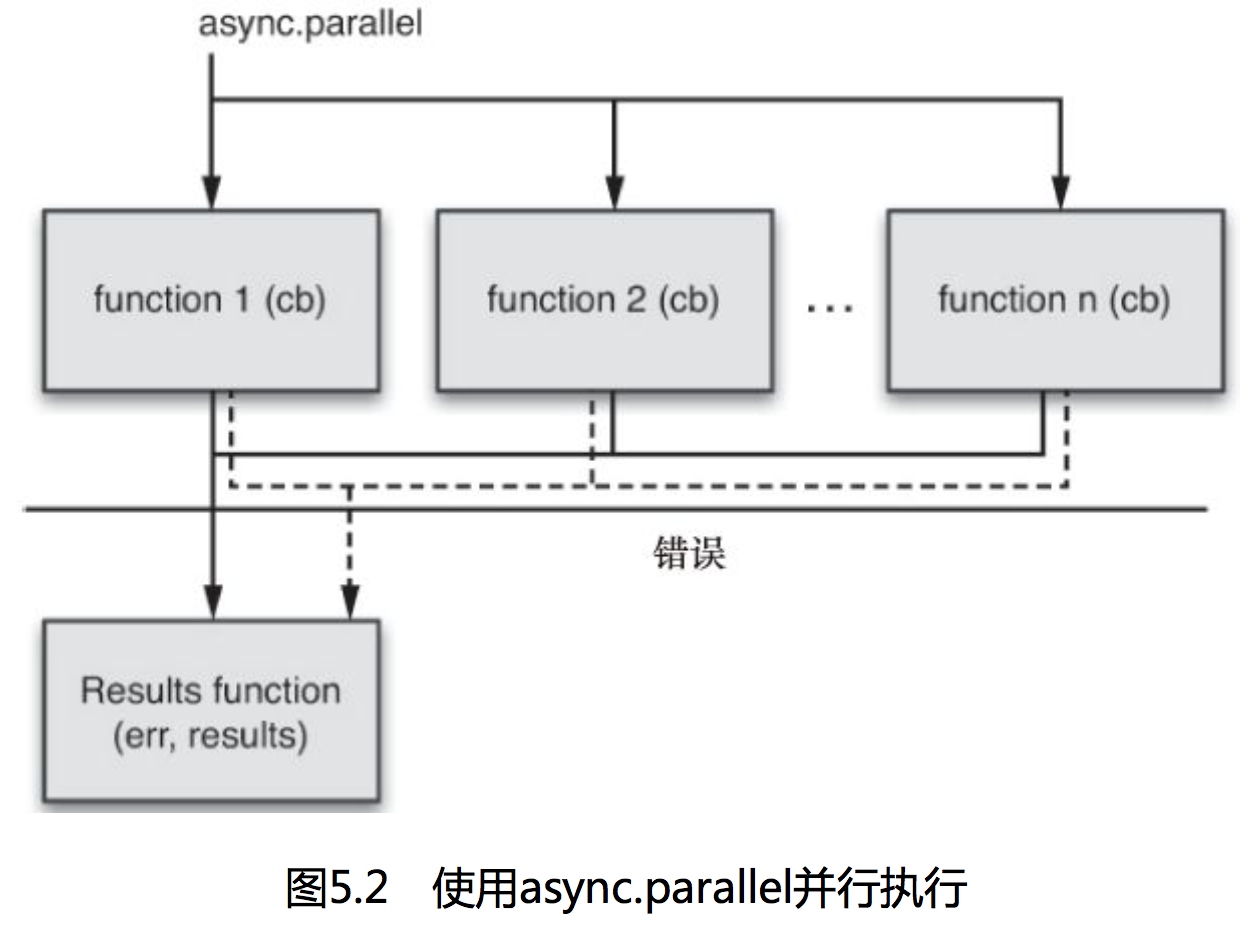
串行和并行组合起来使用
功能最强大的函数是async.auto,能够让我们将顺序执行和非顺序执行的函数混合起来成为一个功能强大的函数序列。
我们传入一个对象,它的key包含了:
- 将要执行的函数
- 一个依赖数组和一个将要执行的函数。这些依赖都是些字符串,是提供给async.auto的对象的属性名。auto函数会等待这些依赖都执行完毕才会调用我们提供的函数。
var async = require("async");
async.auto({
numbers: (callback) => {
setTimeout(() => {
callback(null, [ 1, 2, 3 ]);
}, 1500);
},
strings: (callback) => {
setTimeout(() => {
callback(null, [ "a", "b", "c" ]);
}, 2000);
},
// do not execute this until numbers and strings are done
// thus_far is an object with numbers and strings as arrays.
assemble: [ 'numbers', 'strings', (thus_far, callback) => {
callback(null, {
numbers: thus_far.numbers.join(", "),
strings: "'" + thus_far.strings.join("', '") + "'"
});
}]
},
// this is called at the end when all other functions have executed. Optional
(err, results) => {
if (err)
console.log(err);
else
console.log(results);
});
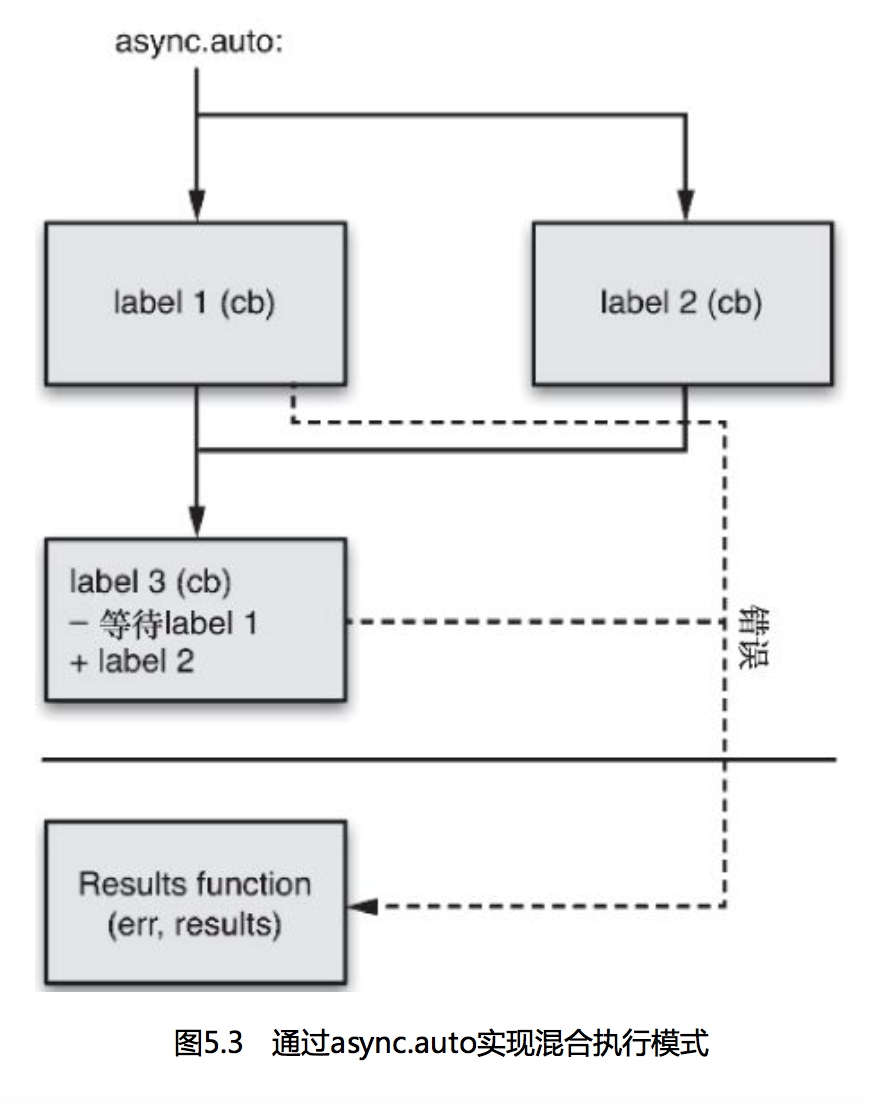
异步循环
async的async.forEachSeries再次帮到我 们,它会遍历我们提供的数组中的每一个元素,为每一个元素调用我 们给定的函数

要简单地遍历循环中的每一个元素,然后让async等待所有的元素执行完毕,可以使用async.forEach,它会以相同的方式被调用,不同之处在于它不会串行地执行函数
扩展Web服务器
我们将学习如何处理静态内容,例如HTML页面、JavaScript文件、CSS文件甚至是图片文件
使用Stream处理静态内容
- Stream最基本的用法是使用on方法
- 将监听函数(listener) 添加到事件(event)上。当事件触发时就会调用所提供的函数。
- readable事件会在输入流(read stream)读取了进程里的一些内容之后触发。
- end事件在Stream不再进行内容读取时触
- error事 件会在错误发生时触发。
const fs = require('fs')
const rs = fs.createReadStream('./simple-stream.js')
let content = '';
rs.on('readable', () => {
let str = '';
let d = rs.read()
if (d) {
if (typeof d === 'string') {
str = d
} else if (typeof d === 'object' && d instanceof Buffer) {
str = d.toString('utf8')
}
content += str
}
})
rs.on('end', () => {
console.log('content: ' + content)
})
使用Buffer操作二进制数据
- 在使用数据流和文件时,实际上主要是在与Buffer 类打交道。
- Buffer暂存二进制数据,将数据转换成其他格式,或将数据写入文件,或将数据打散并重新组合。
- 缓冲对象的length属性并不会返回内容的实际大小,而是返回缓冲本身的大小
const str = 'my name is xxx'
const buffer = new Buffer(1000)
buffer.write(str)
console.log(buffer.length)

- 有时,字符串的字符长度和字节长度并不相等

- 要将缓冲转换成字符串,需使用toString方法。一般都是将缓冲转换成UTF-8字符串
buffer.toString('utf8')
- 使用concat连接两个buffer
const buffer = new Buffer('my name is xxx')
const buffer2 = new Buffer('i am 18 years old')
const buffer3 = Buffer.concat([buffer, buffer2])
console.log(buffer3.toString('utf8'))
在Web服务器中使用Buffer处理静态文件
编写一个小小的Web服务器,这个服务器会 使用Node的Buffer来处理静态内容(一个HTML文件)
const http = require('http')
const fs = require('fs')
const STATIC_PATH = '/content/'
const isStaticFileRequest = (req) => {
return req.method.toLowerCase() === 'get' && req.url.substr(0, STATIC_PATH.length) === STATIC_PATH
}
const contentTypeForPath = (path) => {
return 'text/html'
}
function serverStaticFile(path, res) {
const rs = fs.createReadStream(path)
const contentType = contentTypeForPath(path)
res.writeHead(200, {'Content-Type': contentType})
rs.on('readable', () => {
const d = rs.read()
if (d) {
if (typeof d === 'string') {
res.write(d)
} else if (typeof d === 'object' && d instanceof Buffer) {
res.write(d.toString('utf8'))
}
}
})
rs.on('end', () => {
res.end()
})
}
function handleIncomingRequest(req, res) {
if (isStaticFileRequest(req)) {
serverStaticFile(req.url.substr(STATIC_PATH.length), res)
} else {
res.writeHead(404, {'Content-Type': 'application/json'})
const result = {error: 'not_found', message: `${req.url} not found`}
res.end(JSON.stringify(result))
}
}
const server = http.createServer(handleIncomingRequest)
server.listen(8080)
- 从url中提取文件路径,使用strem读取文件内容后,写入到res当中
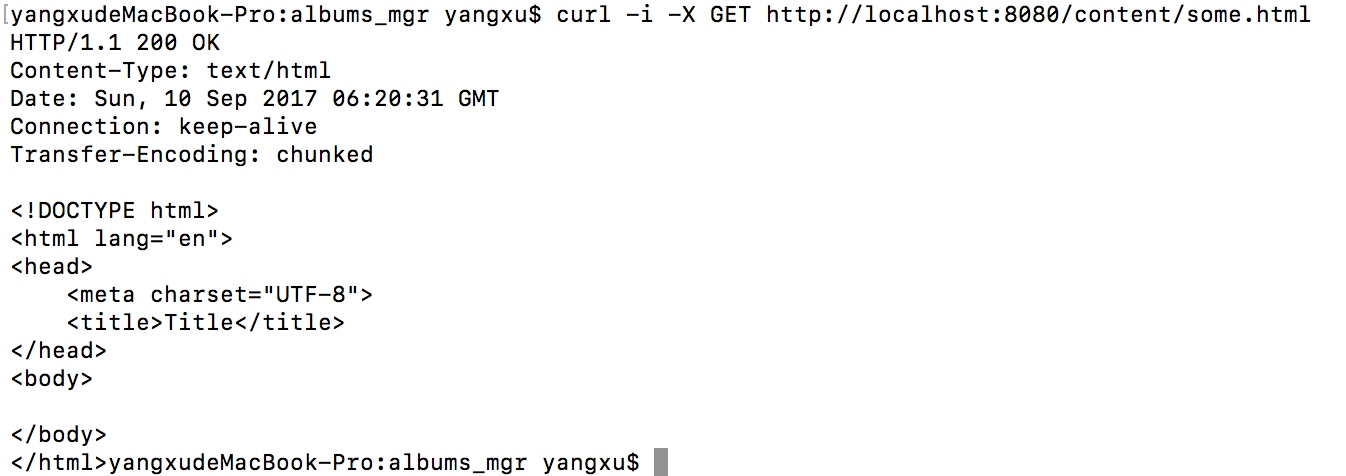
- 但是,当我们访问一个不存在的文件时,会得到空的返回
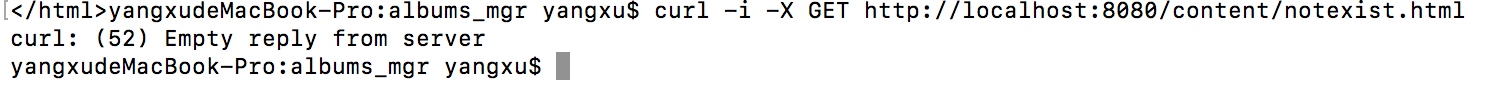
- 添加流处理的错误监听,当访问不存在文件时,返回404
rs.on('error', () => {
res.writeHead(404, {'Content-Type': 'application/json'})
const result = {error: 'not_found', message: `${path} not found`}
res.end(JSON.stringify(result))
})

- 升级contentTypeForPath方法,根据文件扩展名判断返回类型
const contentTypeForPath = (file) => {
const ext = path.extname(file)
switch (ext.toLowerCase()) {
case '.html': return 'text/html'
case '.js': return 'text/javascript'
case '.css': return 'text/css'
case '.jpg':
case '.jpeg': return 'image/jpeg'
default: return 'text/plain'
}
}
- 通过curl获取文件

- 从数据流(上面例子中的rs)到数据流(res)的数据传递是很常见的场景,Node.js的Stream类有一个很便捷的方法来为你做这件事:pipe。
function serverStaticFile(path, res) {
const rs = fs.createReadStream(path)
const contentType = contentTypeForPath(path)
res.writeHead(200, {'Content-Type': contentType})
rs.on('error', () => {
res.writeHead(404, {'Content-Type': 'application/json'})
const result = {error: 'not_found', message: `${path} not found`}
res.end(JSON.stringify(result) + '\n')
})
rs.pipe(res)
}
事件
- Stream实际上是Node.js的Event类的子类
- JavaScript文件中Event类提供连接和触发事件的所有功能
- 可以继承这个类来创建自己的事件触发类
const events = require('events')
class Downloader extends events.EventEmitter {
downloadByUrl(url) {
const self = this;
self.emit('start', url)
setTimeout(function() {
self.emit('end', url)
}, 2000)
}
}
const downloader = new Downloader()
downloader.on('start', (path) => {
console.log('start download: ' + path)
})
downloader.on('end', (path) => {
console.log('end download: ' + path)
})
downloader.downloadByUrl('http://github.com')
在客户端组装内容:模板
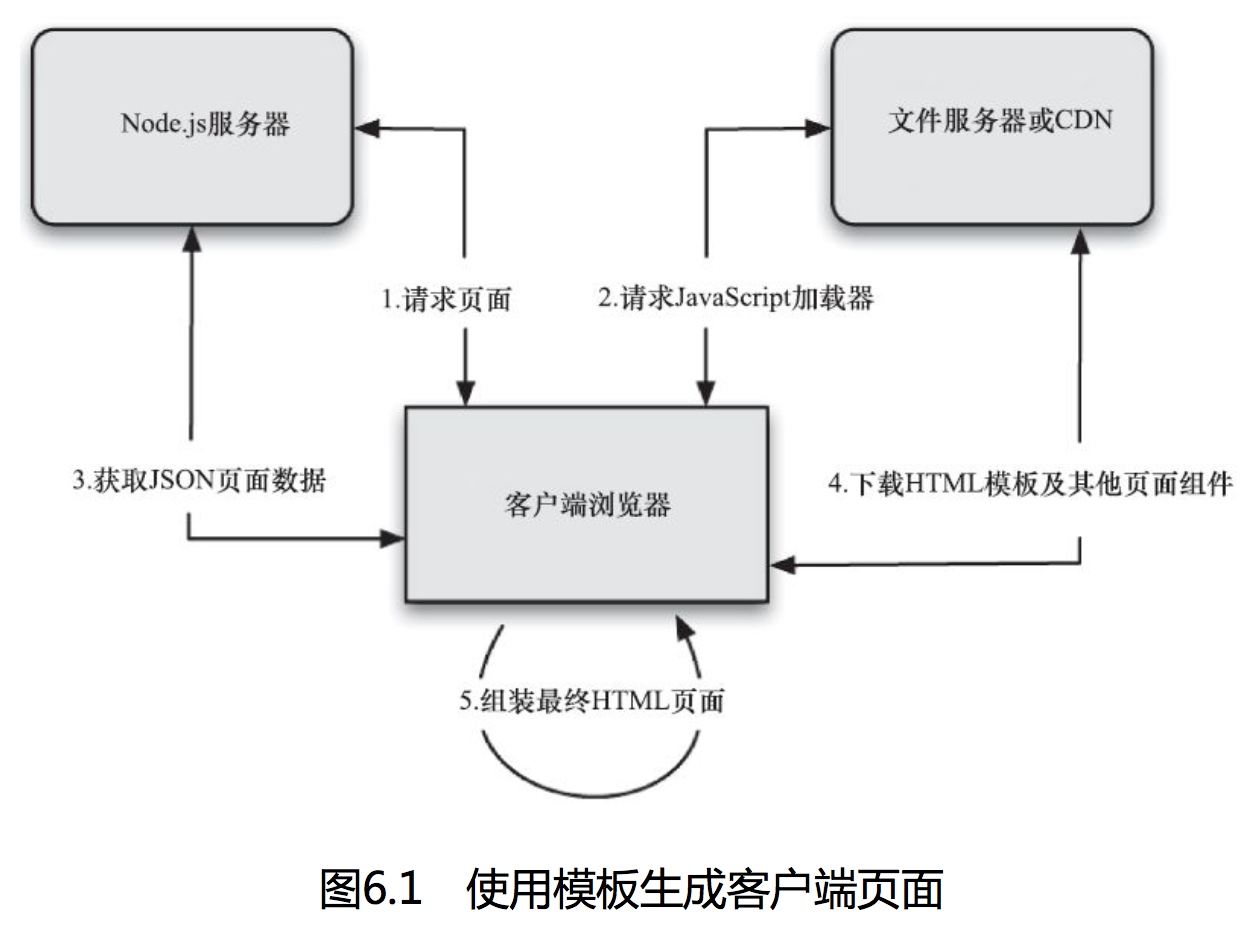
- 充分利用cdn网络和客户端缓存,获取模板文件
- 服务端只处理数据并返回json结果
- 利用客户端的计算能力进行组装