入门 全局变量:Node环境
第一部分 Node基础
- Node.js拥有很小的标准库来为模块开发人员提供底层API
- 理解底层模块可以帮助分析第三方模块
source: https://github.com/alexyoung/nodejsinaction
- 入门
- 全局变量:Node环境
- Buffers:使用比特、字节以及编码
- Events:玩转EventEmitter
- 流:最强大和最容易误解的功能
- 文件系统:通过异步和同步的方法处理文件
- 网络:Node真正的“Hello World”
- 子进程:利用Node整合外部应用程序
第一章 入门
- 为什么要使用Node
- Node的主要特性
- 构建第一个Node应用
JavaScript与生俱来的callback特性,使得在服务端实现异步IO极为方便,而在其他平台下,往往需要其他类库的支持。
Node入门
- Node是一个针对网络应用开发的平台
- 基于Google的V8引擎
- 涵盖了从TCP服务端到同步或异步的文件管理
- 非阻塞式IO能够最大限度的利用服务器的I/O资源
- 在Node的支持下,可以在单线程模型下完成异步操作,避免多线程引入的复杂性
Node的强项
- 有效的分配小块信息
- 处理潜在的网络速度慢的连接
- 容易扩展为多个处理器或服务器
- 使用JavaScript来构建业务逻辑模型
- 不使用C语言来开发迎合特定网络的服务器程序
- 已有JavaScript积累积累的团队
- 轻量的服务器,和浏览器端JavaScript结合
例如:
- 广告分布系统
- 游戏服务器
- 内容管理系统、博客
- 网络爬虫
Node的主要特性
- 标准类库
- 模块系统
- npm
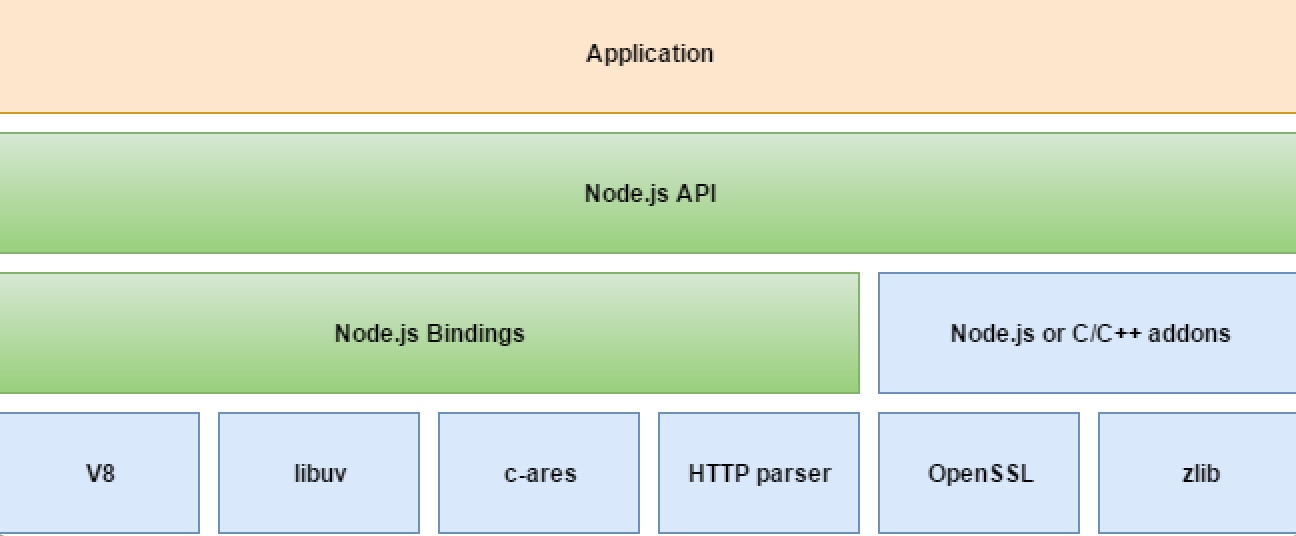
标准类库
标准类库包括二进制类库(libuv,为网络以及文件系统提供了快速的事件轮循和非阻塞I/O)和核心模块两部分组成。
-
EventEmitter事件的接口 - 大多数的核心模块都继承于他:Stream、网络、文件系统等
-
Stream:高可扩展的I/O基础 - 被用来在不可预测的输入下创建数据,多个流之间可以进行连接
-
FS:处理文件 - 包含同步和异步两种模式
-
网络:创建网络客户端与服务端 - 网络模块是http的基础
-
全局对象与其他模块 - http、net、fs等模块;process、console等全局变量
构建一个Node应用
如何开始一个新的Node项目 如何创建自己的Stream类 如何编写运行一个简单的测试
功能:创建一个Stream类接受文本输入,记录通过正则表达式匹配的单次,在文件流发送完成后把结果通过一个事件发布出去。
创建项目
$ mkdir first-project
$ cd first-project/
$ npm init
npm init 创建一个模块并初始化package.json,让这个模块无论多小,都可以方便的引入其他库,并且在今后发布、共享
自定义流 countstream.js
const Writable = require('stream').Writable
class CountStream extends Writable { // 继承可写入流
constructor(matchText, options) {
super(options)
this.count = 0
this.matcher = new RegExp(matchText, 'ig') // 创建一个忽略大小写的正则对象
}
_write(chunk, encoding, cb) { // Node的Writable类会调用 _write 方法
const matches = chunk.toString().match(this.matcher) // 把当前输入转换为字符串,并进行匹配
if (matches) {
this.count += matches.length
}
cb()
}
end() { // 流结束时,Node的Writable会调用end方法
this.emit('total', this.count) // 输入流结束时,出发total事件
}
}
module.exports = CountStream
使用CountStream:创建index.js
const CountStream = require('./src/countstream')
const http = require('http')
const countStream = new CountStream('book') // 初始化自定义流
http.get('http://www.manning.com', function(res) { // 请求网页
res.pipe(countStream) // 以管道的方式连接到countStream
})
countStream.on('total', (count) => { // 监听total事件,打印结果
console.log(`Total matches: ${count}`)
})
在命令行执行:
$ node index.js
使用流,不必关心网络速度或者总大小,它会把内容一块一块的进行处理
编写测试
Node内置了assert模块用于提供断言
const assert = require('assert')
const fs = require('fs')
const CountStream = require('./src/countstream')
const countStream = new CountStream('example')
let passed = 0
countStream.on('total', (count) => {
assert.equal(count, 1) // 断言匹配数
passed += count
})
fs.createReadStream(__filename).pipe(countStream) // 将当前文件创建为流
process.on('exit', () => {
console.log(`Assertions passed: ${passed}`)
})
可以将测试命令加入到npm到package.json中

之后便可以通过npm run test执行测试
第二章 全局变量:Node环境
- 使用模块
- 不使用其他模块能做什么
- process和console对象
- Timers
-
模块
模块被用来组织大型项目和分发Node项目
安装与加载模块
安装三方模块:
$ npm install express
or
$ yarn add express
通过require加载模块:
const express = require('express')
- npm是与Node一起发布到包管理器
- 每个三方模块都提供了自己都readme文件和相关依赖
- 模块被安装在./node_modules目录下,或者通过npm install -g xxx参数安装在全局环境
- 通过npm search命令执行搜索,支持正则表达式匹配
创建与管理模块
除了安装与分发开源项目,本地模块可以用来组织项目
- Node通过内置都CommonJS模块系统加载模块
- 方法、变量都可以从一个文件中export出来
- exports对象的作用域实在一个模块内
- 单独对象的导出可以使用module.exports,多个对象的导出使用exports
// 单个导出 single-export.js
module.exports = function() {}
// 多个导出 multiple-export.js
exports.func1 = function() {}
exports.func2 = function() {}
// 使用场景
const func = require('./single-export')
func()
const m = require('./multiple-export')
m.func1()
m.func2()
- 一个模块一旦被加载,便会进行缓存
- 卸载模块
delete require.cache(require.resolve('./single-export')
加载一组模块
Node可以将目录作为模块,可以把相关的模块按逻辑关系组合起来
- 在目录中创建index.js文件,把所有相关模块一起导出
// group/index.js
module.exports = {
one: require('./one'),
two: require('./two'),
}
// group/one.js
module.exports = function() {console.log('one')}
// use
const group = require('./group')
group.one() // 输出:one
- 在目录下添加package.json
- 当加载一个文件时,会寻找.js, .json, .node为后缀的文件
使用路径
Node提供了类库来找到当前路径、目录或模块的路径
console.log('__dirname', __dirname)
console.log('__filename', __filename)
// 输出
// __dirname /Users/yangxu/Documents/projects/demo/nodejs-in-practice/first-project
// __filename /Users/yangxu/Documents/projects/demo/nodejs-in-practice/first-project/index.js
- 使用path模块拼接路径
const path = require('path')
path.join(__dirname, 'views', 'view.html')
标准IO以及console对象
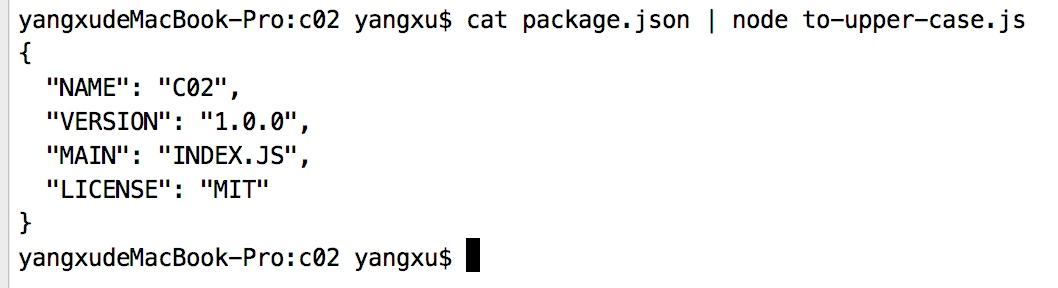
导入或导出数据 - 使用process.stdin和process.stdout
- process.stdout是一个可写的stream
process.stdin.resume() // 通知stream准备读取数据
process.stdin.setEncoding('utf8') // 设置编码
process.stdin.on('data', (text) => { // 收到数据时
process.stdout.write(text.toUpperCase()) // 转换为大写
})
- 基于linux管道的调用:
$ cat package.json | node to-upper-case.js
打印日志消息
- 使用console.log, console.info, console.error, console.warn打印不同级别的日志
- 格式化输出(内容的格式化是通过util.format来实现的)
console.log('Hello %s, i am %d. %j', 'yangxu', 18, {name: 'yangxu'}) - console.error将内容写入错误流,可以在linux中将错误消息重定向(2句柄代表错误流,1代表输出流,0代表输入流)
$ node some.js 2> error-file.log - 使用console.trace()进行调用栈的追踪
性能基准测试
使用console.time(‘label’)和console.timeEnd(‘label’)计算执行时间
操作系统与命令行
process对象能够用来获取系统信息,并通过退出码和信号量与其他进程通信
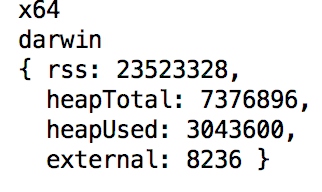
查询操作系统
console.log(process.arch)
console.log(process.platform)
console.log(process.memoryUsage())
传递命令行参数
console.log(process.argv)
/*
[ '/usr/local/bin/node',
'/Users/yangxu/Documents/projects/demo/nodejs-in-practice/c02/read-file.js',
'-h' ]
*/
- 参数解析模块:optimist commander
退出程序
Node允许在退出程序的时候给出一个退出码
process.exit(0) // 正常退出
process.exit(1) // 异常退出
退出信号量
Node程序可以响应其他进程发出的信号
- process对象是一个EventEmitter对象,可以添加监听器
// to-be-killed
process.stdin.resume()
process.on('SIGHUP', () => {
console.log('Reloading configuration...')
})
console.log(`PID ${process.pid}`)
// killer
process.kill(process.argv[2], 'SIGHUP')
- process.kill并不代表杀死进程,而是发送一个信号
使用timer延迟执行
setTimeout与setInterval
const monitor = () => {
console.log(process.memoryUsage())
}
const id = setInterval(monitor, 1000)
id.unref() // 程序停止后,告知node停止计时器
setTimeout(() => {
console.log('Done')
}, 5000)
安全的操作异步接口
Node提供的更有效的延迟执行:process.nextTick
- nextTick将操作放在下一次事件轮询的队列头上,比setTimeout更有效率
可视化事件轮询:setImmediate和process.maxTickDepth
- setImmediate和clearImmediate接受一个回调函数和可选的参数,在下一次IO事件之后,并在setTimeout和setInterval之前执行
Use setImmediate if you want to queue the function behind whatever I/O event callbacks that are already in the event queue. Use process.nextTick to effectively queue the function at the head of the event queue so that it executes immediately after the current function completes.
So in a case where you’re trying to break up a long running, CPU-bound job using recursion, you would now want to use setImmediate rather than process.nextTick to queue the next iteration as otherwise any I/O event callbacks wouldn’t get the chance to run between iterations.