Buffer:使用比特、字节以及编码 Events:玩转EventEmitter 流:最强大和最容易误用的功能
第三章 Buffers 使用比特、字节以及编码
- 介绍Buffer数据类型
- 修改数据编码
- 二进制文件转化为JSON格式
- 创建自定义对二进制协议
-
介绍
历史上JavaScript对二进制支持欠佳,其自身没有提供一个良好对方式去处理原始对内存数据,出于对性能对考虑,Node关于原始数据对处理都在Buffer数据类型中。
Buffers是代表原始堆的分配额的数据类型,在JS中使用类数组对方式来使用。
修改数据编码
文件操作以及很多网络操作都会将数据作为Buffer返回
const fs = require('fs')
fs.readFile('./package.json', (err, buf) => {
console.log(Buffer.isBuffer(buf)) // true
})
转换为其他格式
const fs = require('fs')
fs.readFile('./package.json', (err, buf) => {
console.log(Buffer.isBuffer(buf))
console.log(buf)
console.log(buf.toString())
console.log(buf.toString('ascii'))
})
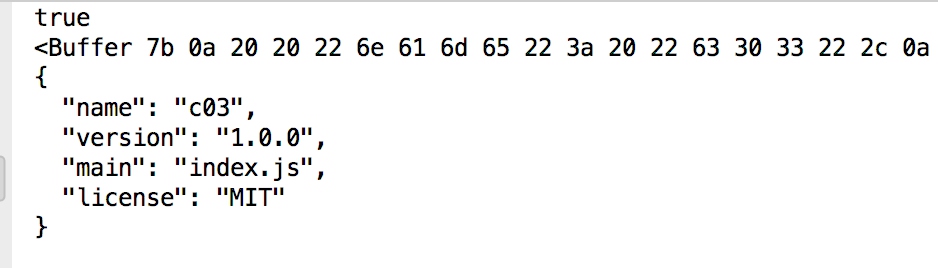
- toString方法默认将Buffer转换为utf8格式的字符串
- 如果知道内容只包含ascii字符,也可以指定编码类型
修改字符串编码
const encoded = new Buffer('yangxu: passwd').toString('base64')
// eWFuZ3h1OiBwYXNzd2Q=
使用Buffer创建png图片的data URIs
const fs = require('fs')
const mine = 'image/png'
const encoding = 'base64'
const data = fs.readFileSync('./images.png').toString(encoding)
const uri = `data:${mine};${encoding},${data}`
console.log(uri)
// data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAMgAAADICAIAAAAiOjnJAAAABGdBTUEAALGPC/...
将dataUri写入文件
const fs = require('fs')
const uri = 'data:image/png;base64,iVBORw0KGgoAAAA...'
const data = uri.split(',')[1]
const buffer = new Buffer(data, 'base64')
fs.writeFileSync('./image_write.png', buffer)
二进制文件转换为JSON
头部信息
- 二进制文件利用头部信息来存储文件相关的基础信息
- Buffer获取索引为0的数据和JavaScript中数组相关操作类似,只是索引是指在内存中的字节位置
- buf[0]代表第0位的八位字节,或无符号的8比特整数,或8比特的正整数
头部信息中1-3位包含最后更新时间,YYMMDD格式
const fs = require('fs')
fs.readFile('./world.dbf', (error, buffer) => {
const header = {}
const date = new Date()
date.setUTCFullYear(buffer[1])
date.setUTCMonth(buffer[2])
date.setUTCDate(buffer[3])
header.lastUpdated = date.toUTCString()
console.log(header) // { lastUpdated: 'Fri, 20 Dec 109 16:31:44 GMT' }
})
4-7 记录数量,32-bit的数字
header.totalRecords = buffer.readUInt32LE(4)
8-9 16-bit数字 头部的字节数 10-11 16-bit数字 记录部分的字节数
header.bytesInHeader = buffer.readUInt16LE(8) header.bytesPerRecord = buffer.readUInt16LE(10)
32-n each 32byte 字段描述,可能包含多个字段的数据 n+1 1byte 字段分隔符
const fs = require('fs')
fs.readFile('./world.dbf', (error, buffer) => {
const header = {}
const date = new Date()
date.setUTCFullYear(buffer[1])
date.setUTCMonth(buffer[2])
date.setUTCDate(buffer[3])
header.lastUpdated = date.toUTCString()
header.totalRecords = buffer.readUInt32LE(4)
header.bytesInHeader = buffer.readUInt16LE(8)
header.bytesPerRecord = buffer.readUInt16LE(10)
const fields = []
let fieldOffset = 32
const fieldLength = 32
const fieldTerminator = 0x0D
const FIELD_TYPES = {
C: 'Character',
N: 'Numeric'
}
while(buffer[fieldOffset] !== fieldTerminator) {
const fieldBuf = buffer.slice(fieldOffset, fieldOffset + fieldLength) // 只是快照,并非拷贝
const field = {
name: fieldBuf.toString('ascii', 0, 11).replace(/\u0000/, ''),
type: FIELD_TYPES[fieldBuf.toString('ascii', 11, 12)],
length: fieldBuf[16]
}
fields.push(field)
fieldOffset += fieldLength
}
console.log(header)
console.log(fields)
})
{ lastUpdated: 'Fri, 20 Dec 109 16:45:03 GMT',
totalRecords: 2127,
bytesInHeader: 225,
bytesPerRecord: 74 }
[ { name: 'CODE\u0000\u0000\u0000\u0000\u0000\u0000',
type: 'Character',
length: 2 },
{ name: 'CNTRY_NAME', type: 'Character', length: 39 },
{ name: 'POP_CNTRY\u0000', type: 'Numeric', length: 10 },
{ name: 'CURR_TYPE\u0000', type: 'Character', length: 16 },
{ name: 'CURR_CODE\u0000', type: 'Character', length: 4 },
{ name: 'FIPS\u0000\u0000\u0000\u0000\u0000\u0000',
type: 'Character',
length: 2 } ]
创建自己的二进制协议
使用良好的二进制协议来传输数据是一种简洁高效的方法
- 首先要确定要传输哪些数据以及如何去表示,确定规范
- 使用掩码来确定数据存放在哪个数据库
- 数据保存以一个在0-255范围内的无符号正数(单字节)的键值标识
- 通过zlib压缩
0 1byte 数据库
1 1byte 数据库键
2-n 0-nbyte 数据
- 数值的二进制表示:
8..toString(2)两个点用来区分小数
const database = [[],[],[],[],[],[],[],[]]
const bitmasks = [1, 2, 4, 8, 16, 32, 64, 128]
function store(buf) {
const db = buf[0]
const key = buf.readUInt8(1)
bitmasks.forEach((bitmask, index) => {
if ((db & bitmask) === bitmask) {
database[index][key] = 'some data'
}
})
}
- 掩码计算利用&运算判断属于哪个db
使用zlib解压缩
const zlib = require('zlib')
const database = [[],[],[],[],[],[],[],[]]
const bitmasks = [1, 2, 4, 8, 16, 32, 64, 128]
function store(buf) {
const db = buf[0]
const key = buf.readUInt8(1)
if (buf[2] === 0x78) { // 判读是否被压缩
zlib.inflate(buf.slice(2), (error, inflatedBuf) => { // 解压缩
if (error) return console.error(error)
const data = inflatedBuf.toString()
bitmasks.forEach((bitmask, index) => {
if ((db & bitmask) === bitmask) {
database[index][key] = 'some data'
}
})
})
}
}
使用zlib压缩并存储数据
const header = new Buffer(2)
header[0] = 8
header[1] = 0
zlib.deflate('my message', (error, deflateBuf) => {
if (error) return console.error(error)
const message = Buffer.concat([header, deflateBuf])
store(message)
})
第四章 玩转EventEmitter
- 使用Node的EventEmitter模块
- 异常管理
- 第三方模块中如何使用EventEmitter
- 如何使用domains模块的events
- EventEmitter的替代品
基础用法:从EventEmitter继承
const events = require('events')
class MusicPlayer extends events.EventEmitter { // 继承
constructor() {
super()
this.playing = false
}
}
const musicPlayer = new MusicPlayer()
musicPlayer.on('play', (track) => { // 监听播放事件
this.playing = true
})
musicPlayer.on('play', (track) => { // 使用多个监听器
console.log(`play ${track}`)
})
musicPlayer.on('stop', () => { // 监听停止事件
this.playing = false
console.log('stop')
})
musicPlayer.emit('play', 'The Roots - The Fire')
setTimeout(() => {
musicPlayer.emit('stop')
}, 1000)
- 移除监听器
musicPlayer.removeAllListeners()
function listener() {
}
musicPlayer.on('play', listener)
musicPlayer.removeListener('play', listener)
- 只触发一次的监听器
musicPlayer.once('play', listener)
混合EventEmitter
当给一个已有当类增加事件能力当时候,使用组合代替继承
class MusicPlayer { // 继承
constructor() {
this.playing = false
}
}
const musicPlayer = new MusicPlayer()
Object.assign(musicPlayer, events.EventEmitter.prototype) // mixin
异常处理
当一个EventEmitter实例发生错误时,通常会发出一个error事件,在Node中,error事件被当作特殊情况,如果没有监听,默认打印堆栈并退出程序
const events = require('events')
class MusicPlayer { // 继承
constructor() {
this.playing = false
}
}
const musicPlayer = new MusicPlayer()
Object.assign(musicPlayer, events.EventEmitter.prototype)
musicPlayer.on('play', (track) => { // 监听播放事件
this.playing = true
})
musicPlayer.on('error', (track) => { // 错误处理
console.log(`play ${track}`)
})
musicPlayer.on('stop', () => { // 监听停止事件
this.playing = false
console.log('stop')
})
musicPlayer.emit('error', 'The Roots - The Fire') // 触发错误
setTimeout(() => {
musicPlayer.emit('stop')
}, 1000)
通过domains管理异常
帮助处理多个EventEmitter实例的异常,例如多个非阻塞的API 能够集中处理多个异步操作,在处理多个相互依赖的I/O操作时非常有帮助
const events = require('events')
const domain = require('domain')
const audioDomain = domain.create() // 创建一个domain
class AudioDevice extends events.EventEmitter {
play() {
this.emit('error', 'not implemented yet')
}
}
const audioDevice = new AudioDevice()
audioDevice.on('play', () => {
audioDevice.play()
})
class MusicPlayer extends events.EventEmitter {
constructor() {
super()
this.audioDevice = audioDevice
}
play() {
this.audioDevice.emit('play')
}
}
audioDomain.on('error', (err) => { // 捕获异常
console.log('error')
})
audioDomain.run(() => { // domain之内执行的代码都会被捕获
const musicPlayer = new MusicPlayer()
musicPlayer.play()
})
高级模式
反射
动态的响应EventEmitter的变化,或者查询他的监听器 利用EventEmitter的特殊事件newListener
const events = require('events')
class MusicPlayer extends events.EventEmitter {
constructor() {
super()
this.playing = false
}
}
const musicPlayer = new MusicPlayer()
musicPlayer.on('newListener', (name, listener) => { // 监听`监听`事件
console.log(name, listener)
})
musicPlayer.on('play', (track) => { // 监听播放事件
this.playing = true
})

探索EventEmitter
大型项目中,模块之间的通信
- Express的app对象
- Redis客户端的RedisClient
组织事件名称
使用一个对象来存储所有事件名,在项目中创建一个统一的位置
MusicPlayer.events = {
play: 'play',
stop: 'stop'
}
第三方模块以及扩展 - EventEmitter的替代方案
- 发布/订阅模式 - 水平扩展分布式集群,借助AMQP、js-signals进行多个Node进程之间的通信
-
第五章 流:最强大和最容易误解的功能
-
流是基于事件的api,借助事件和非阻塞I/O库,流模块允许在可用的时候动态处理,在不用的时候释放
- 什么是流和如何使用
- 如何使用Node集成的流API
- 流API在Node0.8版本以下的使用
- 0.10版本以后的流的原始类
- 测试流的策略
-
流的简介
流适合做什么:
- 内置 - Nodejs的很多内置模块
- HTTP - 网络技术
- 解析器 - xml、json等解析模块
- 浏览器 - 被客户端共享等模块
- Audio - 声音模块
- RPC - 进程间通信
- 测试 - 友好的测试工具库
- 控制、元、状态 - 对流对更加抽象应用
当处理大文件压缩、归档、媒体文件和巨大的日志文件等的时候,内存的使用就成为问题,无法一次性加载所有内容。这时候就需要应用流,配合一个合适的缓冲区,每次只处理部分数据
新版本和老版本中的流
- 0.10版本对流对API进行了重大更新,老版本继续兼容
- 新版本API语法更加严格,但是功能更加灵活
- 新版本模型中,从一个可读流开始,到一个可写流结束
新版流中的可用类
- stream.Readable - 用于在IO上获取数据
- stream.Writable - 用于在输出的目标写入数据
- stream.Duplex - 一个可读和可写的流,例如网络连接
- stream.Transform - 一个会以某种方式修改数据的双工流,没有输入数据要匹配输出数据的限制
内置流
通过内置的流来实现静态Web服务器
第一个版本:
const fs = require('fs')
const http = require('http')
http.createServer((req, res) => {
fs.readFile(__dirname + '/index.html', (err, data) => {
if (err) {
res.statusCode = 500
res.end(String(err))
} else {
res.end(data)
}
})
}).listen(8000)
这个版本存在一个问题,readFile将内容读取到内存后,返回给前台请求;当文件过大时适应性无法保证
第二个版本,数据通过管道输出到res请求响应:
const fs = require('fs')
const http = require('http')
http.createServer((req, res) => {
fs.createReadStream(__dirname + '/index.html').pipe(res)
}).listen(8000)
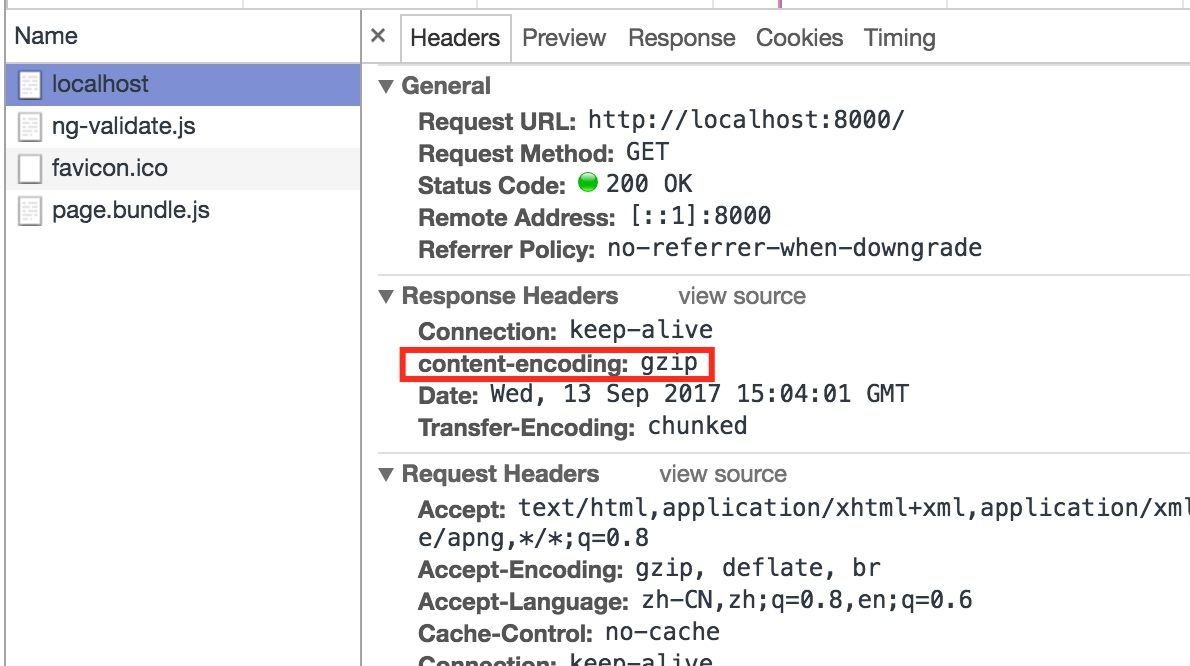
第三个版本,对返回数据进行gzip压缩:
const fs = require('fs')
const http = require('http')
const zlib = require('zlib')
http.createServer((req, res) => {
res.writeHead(200, {'content-encoding': 'gzip'})
fs.createReadStream(__dirname + '/index.html')
.pipe(zlib.createGzip())
.pipe(res)
}).listen(8000)
流的错误处理
流继承于事件类,意味着提供了标准明晰的错误处理方式。
const fs = require('fs')
const stream = fs.createReadStream('not-exist')
stream.on('error', (err) => {
console.trace()
console.error(err)
})
使用第三方模块
在Express中使用流
一个简单的express应用如下:
const express = require('express')
const app = express()
app.get('/', (req, res) => {
res.send('Hello world')
})
app.listen(3000)
res对象实际上是一个response对象,继承自http.ServerResponse,express集成了一种方式让res.send方法能够使用流。
使用流的express应用:
const express = require('express')
const stream = require('stream')
const util = require('util')
const app = express()
class StatStream extends stream.Readable {
constructor(limit) {
super()
this.limit = limit
}
_read(size) {
if (this.limit === 0) {
this.push(null) // push()无法终止流
} else {
this.push(util.inspect(process.memoryUsage()))
this.push('n')
this.limit--
}
}
}
app.get('/', (req, res) => {
const statStream = new StatStream(10)
statStream.pipe(res)
})
app.listen(3000)
使用流基类
正确的选择基类
- Readable - 包装一个底层的IO数据源
- Writable - 发送数据或者从程序中获取输出到其他地方使用
- Transform - 解析数据并修改
- Duplex - 包装一个数据源,并且可以接收消息
- PassThrough - 从流中提取数据,并且不修改它
实现一个可读流
- 继承stream.Readable
- 实现_read方法
- 调用push(null)结束流
代码参考上文“在Express中使用流”
实现一个可写流
- 继承stream.Writable
- 实现_write方法
const stream = require('stream')
class GreenStream extends stream.Writable {
_write(chunk, encoding, callback) {
process.stdout.write('u001b[32m' + chunk + 'u001b[39m')
callback()
}
}
process.stdin.pipe(new GreenStream())
使用双工流转换和接收数据
- 继承Duplex实现 ```js const stream = require(‘stream’)
class HungryStream extends stream.Duplex {
constructor() {
super()
this.waiting = false
}
_write(chunk, encoding, callback) {
process.stdout.write('u001b[32m' + chunk + 'u001b[39m')
callback()
}
_read(size) {
if (!this.waiting) {
process.stdout.write('Feed me >')
this.waiting = true
}
} }
process.stdin.pipe(new HungryStream()).pipe(process.stdout)
- 双工流的优势是处理管道之间的关系
### 使用转换流解析数据
- 流被长期用来实现高效的转换器
```js
const stream = require('stream')
const fs = require('fs')
class CSVParser extends stream.Transform {
constructor() {
super()
this.value = ''
this.headers = []
this.values = []
this.line = 0
}
addValue() {
if (this.line === 0) {
this.headers.push(this.value)
} else {
this.values.push(this.value)
}
this.value = ''
}
toObject() { // 当前行转换为json格式
const obj = {}
for (let i = 0; i < this.headers.length; i++) {
obj[this.headers[i]] = this.values[i]
}
return obj
}
_transform(chunk, encoding, done) {
chunk = chunk.toString()
for (let i = 0; i < chunk.length; i++) {
const c = chunk.charAt(i)
if (c === ',') { // 读取单元格结束
this.addValue()
} else if (c === 'n') { // 读完一行
this.addValue()
if (this.line > 0) { // 内容行,转换为json
this.push(JSON.stringify(this.toObject())) // 使用push方法推送到输出
}
this.values = [] // 清空内容缓存
this.line++
} else { // 继续读取单元格
this.value += c
}
}
}
}
const parser = new CSVParser()
fs.createReadStream(__dirname + '/sample.csv')
.pipe(parser)
.pipe(process.stdout)
- 输入内容自动进入transform方法
- 使用push方法推送到输出
高级模块与优化
流基类接受各种选项定制他们的行为,而且其中一些可以用来调整性能
创建一个流的基准测试
const fs = require('fs')
const zlib = require('zlib')
function benchStream(inSize, outSize) {
const time = process.hrtime() // 纳秒级起始事件
let watermark = process.memoryUsage().rss
const input = fs.createReadStream('/usr/share/dict/words', {
bufferSize: inSize // 设置读入缓冲区大小
})
const gzip = zlib.createGzip({
chunkSize: outSize // 设置压缩缓冲区大小
})
const output = fs.createWriteStream('out.gz', {bufferSize: inSize})
const memoryCheck = setInterval(() => {
const rss = process.memoryUsage().rss
if (rss > watermark) {
watermark = rss // 记录内存峰值
}
}, 50)
input.on('end', () => {
clearInterval(memoryCheck)
const diff = process.hrtime(time) // 计算执行时间
console.log([
inSize, outSize, (diff[0] * 1e9 + diff[1]) / 1e6, watermark / 1024
].join(','))
})
input.pipe(gzip).pipe(output) // 读入文件经过压缩后,写入结果
return input
}
console.log('file size, gzip size, ms, RSS')
let fileSize = 128
let zipSize = 5024
function run(times) {
benchStream(fileSize, zipSize).on('end', () => {
times--
fileSize *= 2 // 每次执行完成后,扩大缓冲区
zipSize *= 2
if (times > 0) { // 递归调用
run(times)
}
})
}
run(10)
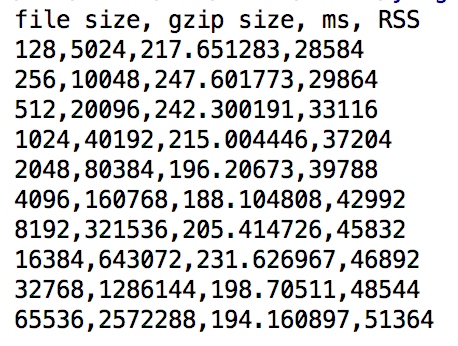
- 随着缓冲区的增大,时间并未出现明显变化,但是峰值内存持续增加
测试流
- 用一些合适的样本数据来驱动流
- 调用read()或write()方法来获取结果
- 对比结果和预期
通过module.exports = CSVParser将之前的csv解析器作为模块
const assert = require('assert')
const fs = require('fs')
const CSVParser = require('./csv-parser')
const parser = new CSVParser()
const actual = []
fs.createReadStream(__dirname + '/sample.csv').pipe(parser)
process.on('exit', () => {
actual.push(parser.read())
const expected = [
{} // 期望的结果
]
assert.deepEqual(expected, actual) // 对比结果
})