子进程:利用Node整合外部应用
第八章 进程:利用Node整合外部应用
在Node的世界里,child_process模块是允许我们在node程序中执行外部程序的
Node允许使用四种方式执行外部应用:
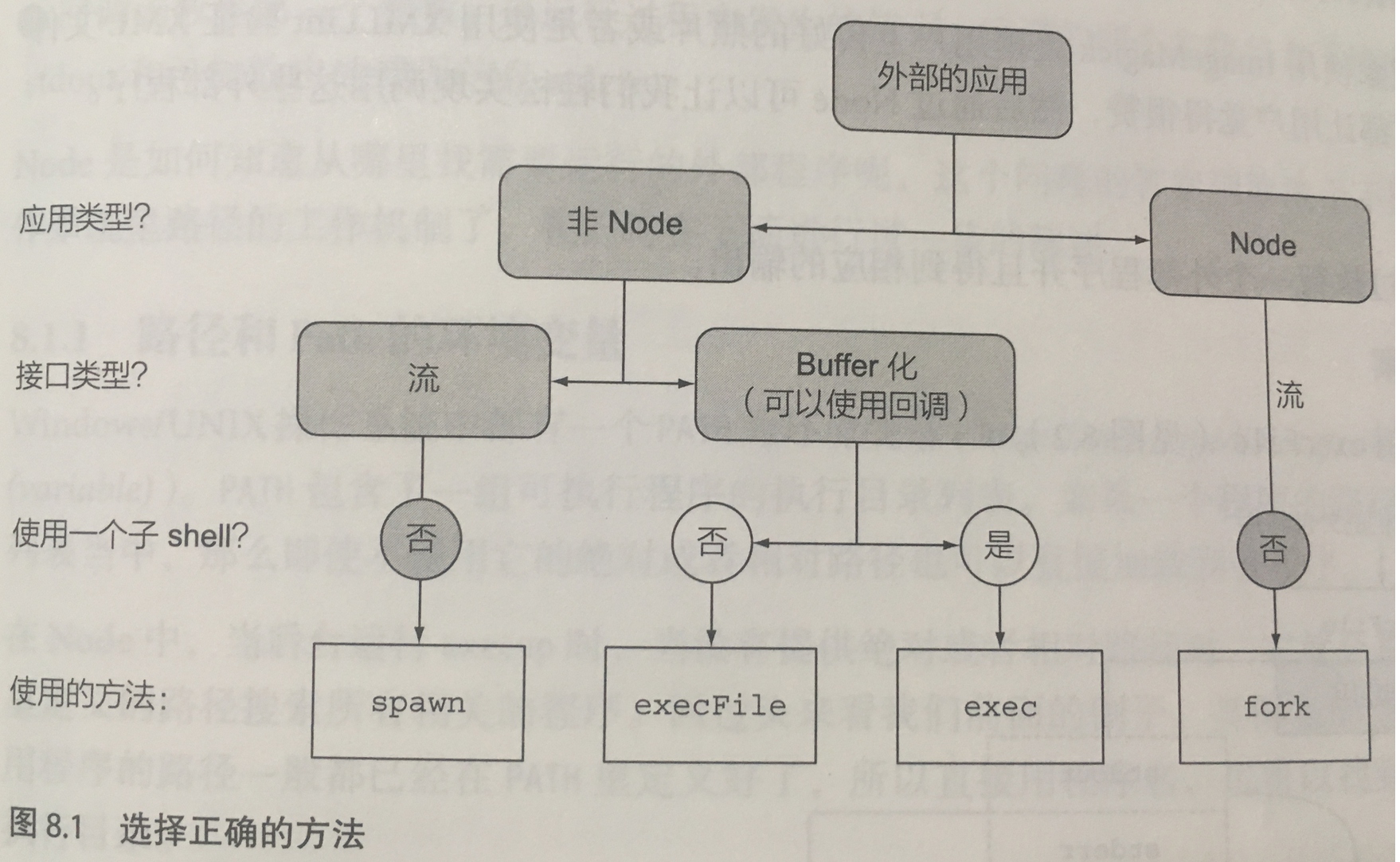
- execFile - 执行外部程序,并且需要提供一组参数,以及一个在子进程退出后的缓冲输出的回调
- spawn - 执行外部程序,并且需要提供一组阐述,以及一个在子进程退出后的输入输出和事件的数据流接口
- exec - 在一个命令行窗口中执行一个或多个命令,以及一个在进程退出后缓冲输出的回调
- fork - 在一个独立的进程中执行一个Node模块,并且需要提供一组参数,以及一个类似spawn方法里的数据流和事件接口,同时设置好父进程和子进程之间的进程间通信
执行外部应用程序
执行一个外部程序获得相应的输出
const cp = require('child_process')
cp.execFile('echo', ['hello', 'world'], (err, stdout, stdin) => {
if (err) console.error(err)
console.log('stdout', stdout)
console.log('stdin', stdin)
})
路径和Path的环境变量
- PATH包含一组可执行程序的执行目录列表
- 在Node中,当后台运行execvp时,如果没有提供绝对或相对路径,就会基于PATH搜索相关程序
- 通过process.env.PATH查看环境变量
- 也可以在执行execFile之前通过process.env.PATH设置环境变量
process.env.PATH += `:a/new/path/to/executable`
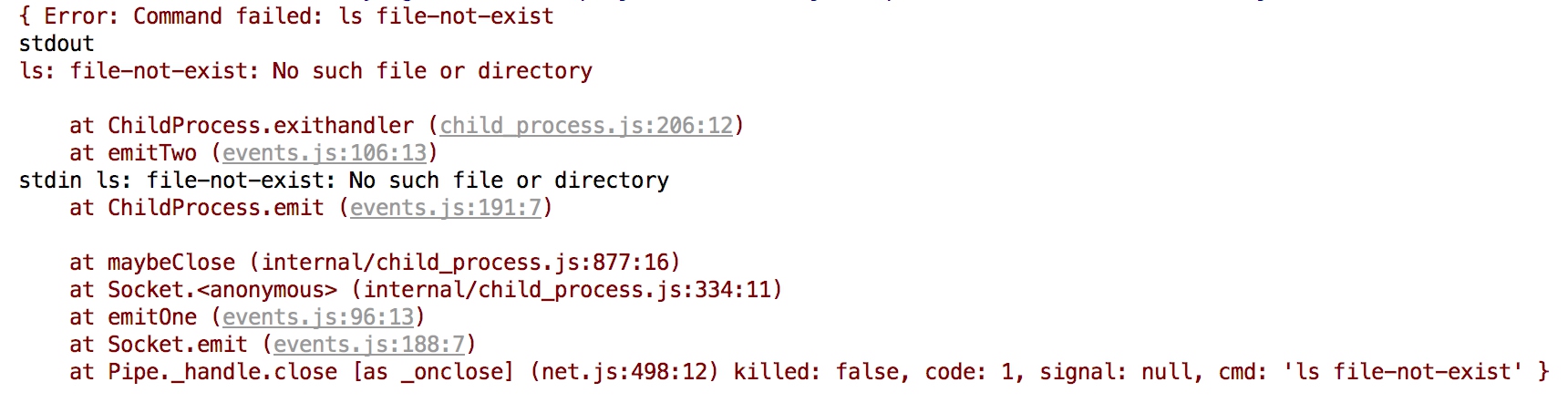
执行外部程序时出现的异常
- 找不到程序时,遇到ENOENT的错误
- Node无权限访问程序,遇到EACCES或者EPERM的错误
- 当外部程序返回非0状态时
const cp = require('child_process')
cp.execFile('ls', ['file-not-exist'], (err, stdout, stdin) => {
if (err) console.error(err)
console.log('stdout', stdout)
console.log('stdin', stdin)
})
流和外部应用程序
- 预期会有大数据量传输的时候
- 希望提高响应效率的时候
const cp = require('child_process')
const child = cp.spawn('echo', ['hello', 'world'])
child.on('error', console.error)
child.stdout.pipe(process.stdout)
child.stderr.pipe(process.stderr)
外部程序的串联调用
- UNIX系统的一个重要哲理:每个程序专注做好一件事,各程序之间通过通用的接口(纯文本)进行相互通信
const cp = require('child_process')
const child = cp.spawn('echo', ['hello', 'world'])
child.on('error', console.error)
child.stdout.pipe(process.stdout)
child.stderr.pipe(process.stderr)
在shell中执行命令
- 使用exec执行一些系统已有的子命令
- exec实际上是调用/bin/sh或cmd.exe来执行命令
- 如果使用用户输入来拼接命令,很有可能出现非法的注入 ```js const cp = require(‘child_process’)
cp.exec(‘cat messy.txt | sort | uniq’, (err, stdout, stdin) => { console.log(stdout) })
### 分离子进程
通过Node打开一个外部应用程序,让他独立运行
- 分离一个衍生的子进程
- 正常情况下父进程终止时,子进程会终结;使用spawn方法可以做到进程分离
```js
const child = cp.spawn('./longrun', [], { detached: true })
父进程和子进程之间的I/O处理
- stdio选项定义了子进程的I/O连接到一个具体的地方
- 值可以是字符串或者数组
- 默认情况下,使用字符串pipe -
stdio: 'pipe' - 数组模式下,0-2号文件解析器,分别对应stdin、stdout、stderr
- 这样依赖stdio的值就连接了父子进程(通过文件)
- 如果想销毁这一连接,可以使用destroy()方法,或者设置为ignore
const cp = require('child_process')
const fs = require('fs')
const outFd = fs.openSync('./longrun.out', 'a')
const errFd = fs.openSync('./longrun.err', 'a')
const child = cp.spawn('./longrun', [], {
detached: true,
stdio: ['ignore', outFd, errFd],
})
引用计数和子进程
- 分离之后,父进程会保留对子进程的引用
- 通过child.unref()来取消计数
执行Node程序
Forking Node模块
-
在处理大数据量计算的时候,将大批量的任务压力分解到一个独立的进程中,通过进程间通信来处理问题
- Node为其他的Node程序之间通信,提供了更好的方式:stdio: [0, 1, 2, ‘ipc’],表示所有的输入和输出都是继承父进程
- 如果希望提供一种和spawn具有一样的默认的I/O配置,可以使用silent: true选项
和forked的Node模块进行通信
- 使用fork方法会开辟一个IPC通道
- 子进程这边会暴露process.on(‘message’)和process.send()
- 父进程这边使用的是child.on(‘message’)和child.send()
- 使用child.disconnect()来断开连接
运行作业
- 创建一个工作池
- 父进程发送一个消息给子进程的时候,期望一个确切的结果
// worker.js
#! /usr/bin/env node
process.on('message', (msg) => {
process.send(parseInt(msg) * 2) // 收到数字,乘2之后返回
})
// worker-pool.js
const cp = require('child_process')
const cpus = require('os').cpus().length // 获取cpu数量,创建尽可能多的fork
module.exports = function (workModule) {
const awaiting = [] // 当前处于排队的任务
const readyPool = [] // 当前可用的worker
let poolSize = 0 // 工作池的大小
return function doWork(job, cb) {
console.log(`poolSize: ${poolSize} readyPool: ${readyPool.length} awaiting: ${awaiting.length}`)
if (!readyPool.length && poolSize > cpus) {
return awaiting.push([doWork, job, cb]) // 如果没有空闲工作者或者数量超过池限制,加入排队
}
const child = readyPool.length
? readyPool.shift() // 如果有空闲资源,直接使用
: (poolSize++, cp.fork(workModule)) // 如果还未超限,创建一个新的fork
let cbTriggered = false // 记录回调是否被执行
child
.removeAllListeners()
.once('error', (err) => {
if (!cbTriggered) { // 避免多次执行回调
cb(err)
cbTriggered = true
}
child.kill() // 杀死子进程
}).once('exit', (code, signal) => {
if (!cbTriggered) {
cb(new Error(`Child exited with code: ${code}`))
}
poolSize--
const childIdx = readyPool.indexOf(child) // 如果子进程因为其他原因退出,已经不可用,在进程池中进行清理
if (childIdx > -1) {
readyPool.slice(childIdx, 1)
}
}).once('message', (result) => {
cb(null, result) // 收到结果后执行回调
cbTriggered = true
readyPool.push(child) // 执行任务结束后,当前子进程作为空闲工作者
if (awaiting.length) {
setImmediate.apply(null, awaiting.shift()) // 如果还有排队任务,在下个周期执行
}
}).send(job)
}
}
使用工作池:
const workerPool = require('./worker-pool')
const runJob = workerPool('./worker.js') // 初始化工作池
runJob(1000, (err, data) => {
if (err) console.error(err)
console.log(data)
})
同步运行
使用execFileSync, spawnSync, execFile同步执行子进程
const cp = require('child_process')
const stdout = cp.execFileSync('echo', ['hello']).toString()
console.log(stdout)
const ps = cp.spawnSync('ps', ['aux'])
const grep = cp.spawnSync('grep', ['node'], {
input: ps.stdout,
encoding: 'utf8',
})
console.log(grep)
const execSyncOut = cp.execSync('ps aux | grep node').toString()
console.log(execSyncOut)
同步子进程中的异常处理
- 如果在同步执行的方法中返回非零状态,会抛出异常
- 使用try/cache捕获异常信息
try {
cp.execFileSync('cat', ['not-exist-file']).toString()
} catch (e) {
console.error(e.status)
console.error(e.stderr)
}